RNDR is a design studio for interactive media that develops ‘tools’ that are only finished by how they are used.
To achieve this, we develop processes, create structures, design visualisations, code programs, and create interactions. The end result can manifest itself across different media, ranging from interactive installations, data visualisations, generative identities, prints and everything in between – often real-time. We are triggered by how information and technology transforms networks, cultures, societies, relationships, behaviours, and interactions between people. Our work explores and engages with hybrid space as it embraces both digital and physical realms.
RNDR was founded in 2017 in The Hague, (NL). Its main members have years of experience as partners, computer scientists, designers, art directors and developers at LUST and LUSTlab.
One of our core projects, and basis for most of our projects, is OPENRNDR, an open source framework for creative coding –written in Kotlin for the JVM– with over 13 years of development. OPENRNDR simplifies writing real-time audio-visual interactive software. OPENRNDR is fundamental for the capacity of RNDR as a studio, as it allows us to realize complex interactive works. OPENRNDR was awarded the Dutch Design Award 2019.
Fields of work
Interactive design (ui/ux), data visualisation, information systems, software tools, interactive installations, media architecture, immersive experiences, interface design, visual identities, generative video, creative coding, exhibition design, graphic design systems, hybrid spaces and platforms, machine learning and artificial intelligence (ai), code and design workshops.
We have worked for or collaborated with
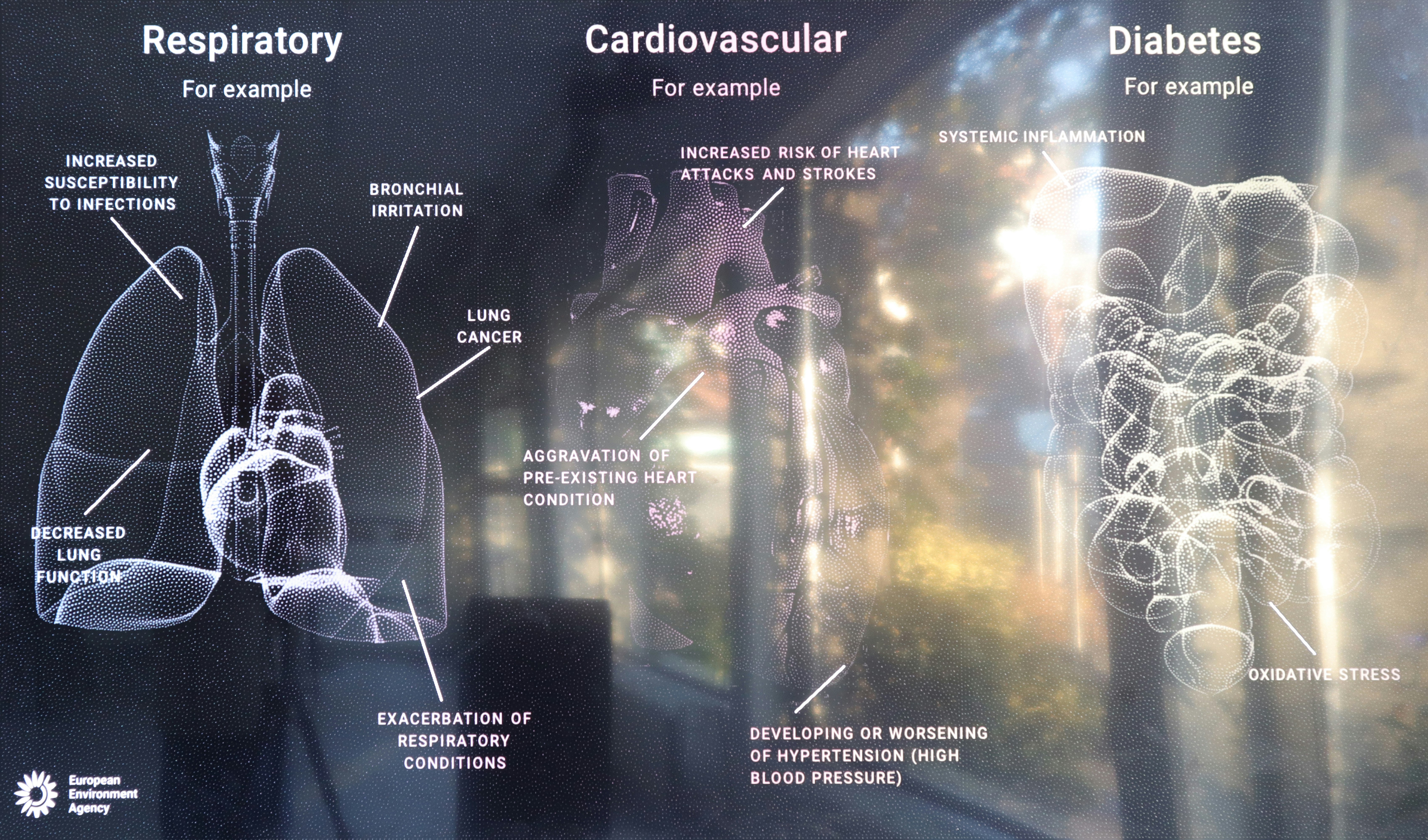
Philips, Audi, Massive Attack, Foto Museum, Autostadt, Stedelijk Museum Amsterdam, DropCity, Google, MoMA New York, IABR, VNG, DoepelStrijkers Architects, Kaan Architects, Buchmesse Frankfurt, European Environment Agency, PARC, Government Summit Dubai, RAP, Technical University Twente, Royal Holloway University, Paradox, Space10, Cooper Hewitt, Hammer Museum, Jacquemus, Holland Festival, RAUM, Civic Architects, The Municipality of The Hague, Vlisco, Police Emergency Center, KPN, Tod’s, Zegna, LI-MA, WTTC, Institute for Future Cities, Makropol, IDFA, UCLA, Artez Arnhem, Ministry of Internal Affairs, Digital Society School, Andrea Caputo Architects, Doesburg vertelt, VNG, Wellcome Trust, Ministry of Economic Affairs, NOI Tech Park, CELEST, Electric Castle, and many more.